
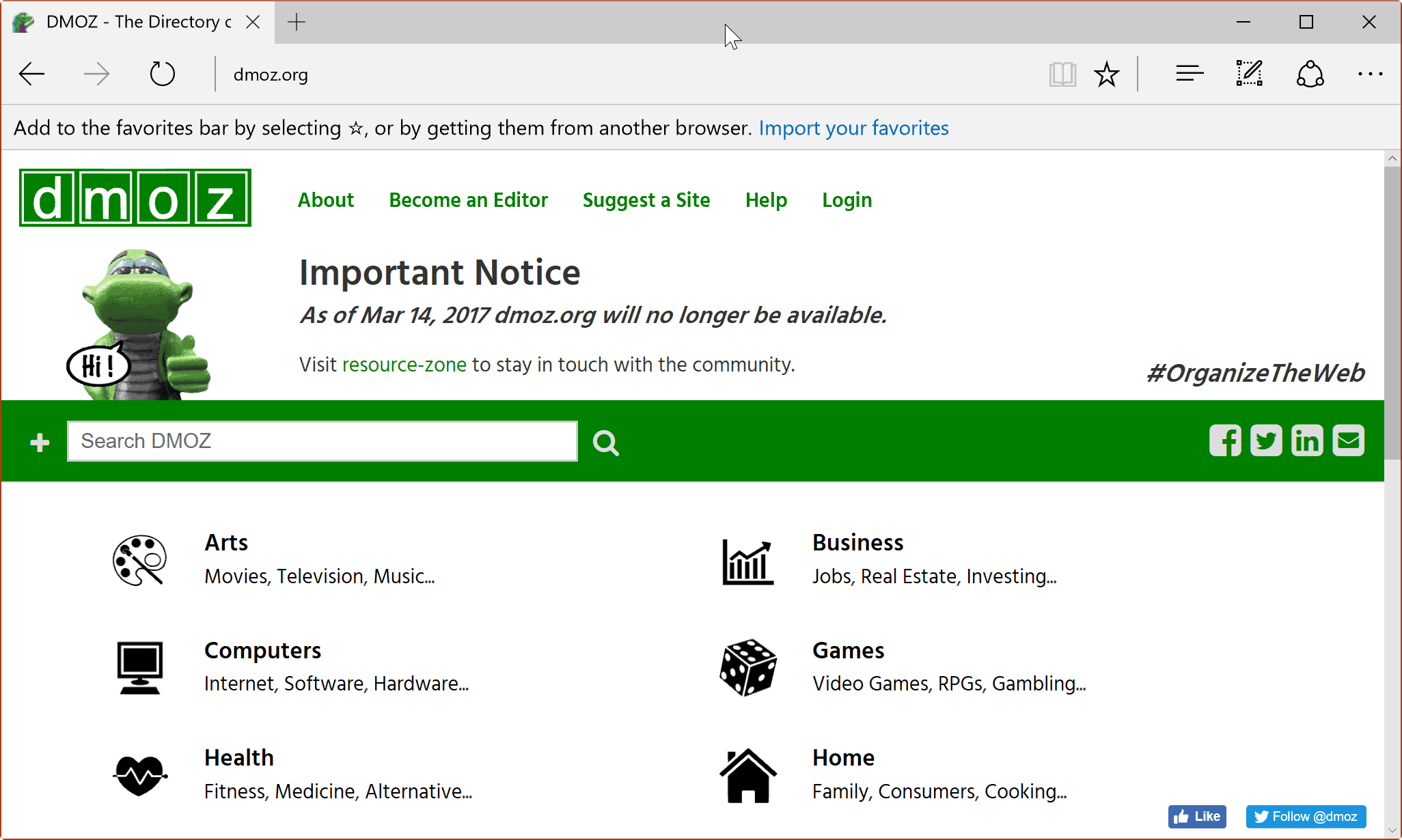
Throughout the history of the internet, SEO has been important for websites. It’s taken many forms, of course; today, we know it as the inclusion of keywords and the structuring of content in such a way that Google’s algorithms can spot said content, but in the 90s, the SEO landscape looked very different.
Sites like DMOZ.org (which is short for “directory.mozilla.org”, a domain name the site used at one point) used to be pivotal for SEO. They were human-run and human-edited web directories that categorised and organised website content, and search engines would often rely on them to understand what content was worth indexing.
Now, however, DMOZ.org is no longer functional. Several mirrors and archives remain active so that you can browse what DMOZ once was, but the site as we know it is no longer being updated. So, what happened to DMOZ? How did this once-great site fall from grace? Let’s take a look at DMOZ’s history.
DMOZ: the early days
DMOZ was founded by programmer Rich Skrenta, who was tired of the directory run by Yahoo, which at the time had many dead links that made it frustrating to navigate. Originally, DMOZ was called GnuHoo, and unlike Yahoo’s limited paid staff members, GnuHoo was edited by a functionally unlimited volunteer base.
In essence, GnuHoo was similar to Wikipedia, albeit without many of the checks and balances that site enjoys. Editors could simply edit any topic they liked, so as you can imagine, many conflicts and problems arose as a result of this. GnuHoo was quickly beset by the kind of issues that an anarchic collective of editors with their own agendas would inevitably fall into.
Unfortunately, the project was also beset by naming problems. Initially, the Free Software Foundation had an objection to the use of “GNU” in the name GnuHoo, and so GnuHoo rebranded as NewHoo. Then, it was Yahoo’s turn to object, prompting another name change for the service to ZURL.
DMOZ is acquired by Netscape
A round of acquisitions subsequently began for DMOZ. It was acquired by Netscape, makers of the popular Netscape Navigator browser, in late 1998, prompting yet another name change to the Open Directory Project. During this time, DMOZ – or ODP – continued to run as a human-edited web directory, containing hierarchy upon hierarchy of organised websites according to category and purpose.
After the Netscape purchase, DMOZ’s star continued to rise, and by April 2013, the project had managed to index over 5 million websites. Google turned to DMOZ for help with indexing websites; in fact, there were times when Google would use snippets written by DMOZ volunteers, because it felt that those snippets were superior in describing the site’s content.
Naturally, DMOZ attracted competition. Other web directories began to spring up, although they didn’t use the Open Directory distribution model, potentially making them less attractive to volunteers (and lest we forget, DMOZ was run pretty much entirely by volunteer staff, which makes its massive amount of indexed websites even more impressive).
Controversies abound
As is the case with many volunteer organisations, DMOZ was also beset by controversies and issues within its organisational structure. Some DMOZ volunteers claimed they’d been duped into joining a commercial organisation they had no interest in being a part of, for instance, and, of course, there’s the general lack of structure within the organisation itself that we mentioned earlier.
Editor controversies also reigned supreme at DMOZ. Accusations of editors giving preferential treatment to their own websites or websites they favoured were rife, and there was infighting among editors regarding policy disagreements and the procedure for banning or punishing editors who misbehaved. To put it simply, DMOZ was not a platform without internal or external disagreements.
DMOZ’s relevance begins to slip away
Despite its dominance during the initial computer boom of the 90s, DMOZ just couldn’t keep up with modern technology, it seems. DMOZ used a complex hierarchical system, and many of its critics claimed that hierarchies didn’t work when it came to web directories; they were too confusing and too badly laid out for any user to want to engage with them.
Shortly after DMOZ was acquired by Netscape, Netscape itself was then acquired by AOL, which agreed to keep DMOZ under its wing. Eventually, however, AOL, which remains active today as a subsidiary of Verizon, would shut down DMOZ owing to a lack of desire to keep the project alive.
So, what happened? Chiefly, we can blame the demise of DMOZ on the emergence of Web 2.0, which emphasised interoperability and ease of use as cornerstones of its operating policies. Users didn’t want to sift through massively complicated hierarchies (as they saw it) anymore; instead, they wanted to quickly and easily access websites they knew were high-quality, and sites like DMOZ were just too old-school for that.
There’s also the fact that Google’s algorithms became more and more sophisticated. Where Google would rely on sites like DMOZ to categorise and organise content to make sure it was worth reading for users, increasingly, the search engine found that it didn’t need to rely on human-edited sites for this. Instead, it could teach its ever more sophisticated algorithms and machine learning processes to recognise high-quality websites by themselves, thus eliminating the middleman.
DMOZ lives…sort of
Of course, just because DMOZ has been shut down, that doesn’t mean its community’s passion for it has vanished. As we’ve said, mirrors for DMOZ exist online, so you can still read and browse its content, and human-edited web directories remain active on the internet, albeit in a diminished capacity.
A semi-official successor to DMOZ, Curlie, also exists. Once you’ve chosen your language, you’ll be taken to a page that looks almost identical to the DMOZ landing page, and you can search the directory for sites and hierarchies as well. Suffice it to say that if you’re sad about the death of DMOZ, you may be mourning prematurely.
